
¿Qué pasa con esos datos observacionales que no se recogen para investigación?
Estaba repasando mis publicaciones el Linkedin y me he dado cuenta de que hay un tema sobre el que publico más. Supongo que de alguna manera se tenía que notar que es un tema que me gusta especialmente.
Se trata de la aplicación de la inferencia causal para evaluar el impacto de una intervención, programa o política aplicada en salud. Pero la aplicación de estas metodologías que a mi más me gusta es aprovechando los datos ya existentes en el sistema, lo que hoy se conocen como datos del mundo real o real world data (RWD). He de confesarte que a mi este nombre no me gusta mucho…pero eso es otro tema.
Antes de seguir quiero hacer un paréntesis para identificar los 2 tipos de datos reales o datos observacionales que podemos encontrar en los sistemas de salud:
- Por un lado están las cohortes epidemiológicas, es decir, aquellos estudios observacionales que se han generado específicamente para investigación, por ejemplo, las grandes cohortes de estudios cardiovasculares o de cáncer.
- Por otro lado, están los datos observacionales que no se recogen para la investigación, y que estarán ahí tanto si nosotros los vamos a utilizar para investigación como si no. Por ejemplo, datos de las historias clínicas, registros, datos que se usan para la gestión de pacientes, para cuestiones administrativas, etc.
El reto está en este segundo grupo de datos observacionales que no se han generado específicamente para investigación, ¿cómo usamos estos datos? ¿cómo los tratamos para poderlos utilizar en investigación?
Ahora sí, vamos a identificar dos situaciones en las que utilizar estos datos ya existentes para aplicar técnicas de inferencia causal y evaluar el impacto de una intervención.
(Nota: a partir de aquí utilizaré solo el término intervención, pero me estaré refiriendo también a un programa, política o a cualquier evento que modifique el curso de un comportamiento).
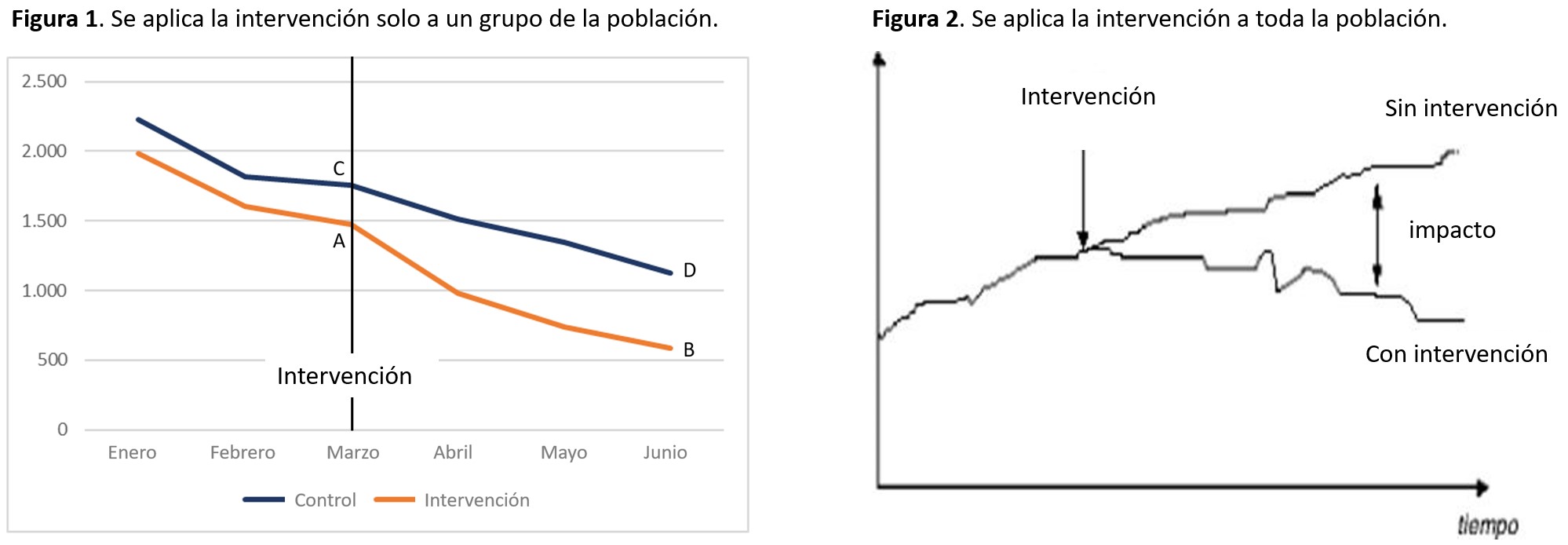
La primera situación y la más habitual en salud, sería cuando se aplica una intervención solo a un grupo de la población (Figura 1), de manera que podemos observar la evolución que llevaban los dos grupos antes de la intervención y ver cómo evolucionan ambos una vez aplicada esta.
Seguro que aquí estás pensando en un ensayo clínico. Es correcto. ¿Pero y si vamos más allá y utilizamos los datos ya existentes en las bases de datos, para emular un ensayo clínico? ¿Por qué no utilizar la información que ya existe en los registros de los hospitales sobre nacimientos para evaluar el impacto de las cesáreas no planificadas en la salud neonatal, por ejemplo?
¿Por qué no utilizar la evidencia científica de las dos fuentes (ensayos clínicos y estudios observacionales) de la mejor forma posible? (post LinkedIn)
Y aun te planteo más preguntas:
¿Qué pasa si la intervención no es posible aplicarla solo a un grupo de la población y se aplica a toda la población sin que podamos evitarlo? Por ejemplo, una pandemia, un programa de cribado, o una reordenación en el territorio de la actividad asistencial de los hospitales, atención primaria, etc. ¿Cómo evaluamos aquí su impacto?
En esta segunda situación (Figura 2), la utilización de estos datos ya existentes será imprescindible para poder evaluar el efecto de una pandemia, de un programa de cribado o de una reordenación de la actividad asistencial.
¿Cómo hubiesen evolucionado los indicadores de salud mental si la pandemia no se hubiera producido?
¿Cómo hubiesen evolucionado los casos de cáncer colorrectal si el programa de cribado no se hubiese implantado en todo el territorio?
¿Cómo hubiesen evolucionado las muertes intrahospitalarias si no se hubiese llevado a cabo la reordenación hospitalaria de cirugía ortopédica y traumatología de alta especialización?
Para responder a estas preguntas, será necesario definir un buen contrafactual, es decir, un buen grupo control basándonos en el comportamiento de esta población antes de la pandemia, programa de cribado o reordenación.
Si a ti también te apasiona este tema, ¡te leo en los comentarios!



{kind=link}
{kind=link}
{kind=link}
{kind=link}